
PyTorchで音声/音楽データを読み込むtorchaudio.loadを使う。torchaudio.loadを使用すると、Tensor型で読み込まれるため、PyTorchでそのまま処理することができ便利です。
backendには、Linux/macOSの場合は"sox_io"、Windowsの場合は"soundfile"がデフォルトで使用されており、ここではbackendが"sox_io"の場合の方法について記載する。
今回用いるサンプル音源を、以下コードを実行して、_sample_dataフォルダにダウンロードする。
import os
import requests
_SAMPLE_DIR = "_sample_data"
SAMPLE_WAV_URL = "https://pytorch-tutorial-assets.s3.amazonaws.com/steam-train-whistle-daniel_simon.wav"
SAMPLE_WAV_PATH = os.path.join(_SAMPLE_DIR, "steam.wav")
os.makedirs(_SAMPLE_DIR, exist_ok=True)
with open(SAMPLE_WAV_PATH, 'wb') as f:
f.write(requests.get(SAMPLE_WAV_URL).content)torchaudio.loadの使い方
第一引数 filepathに、音源のファイルパスを指定する。音源がTensor型で[channel, time]で返ってくる。また、サンプリング周波数も返ってくる。ステレオ(2ch)のため、表示すると青線と赤線が確認できる。
import torch
import torchaudio
import matplotlib.pyplot as plt
waveform, sample_rate = torchaudio.load(filepath=SAMPLE_WAV_PATH)
print(waveform.shape)
# torch.Size([2, 109368])
print(sample_rate)
# 44100
plt.plot(waveform.t().numpy());
第二引数frame_offsetで、音源の読み込み開始サンプル点を指定できる。ここでは、開始サンプルを10000に設定しているため、先ほどの信号の長さより、10000ポイントサンプルが少ないことが確認できる。
waveform, sample_rate = torchaudio.load(filepath=SAMPLE_WAV_PATH, frame_offset=10000)
print(waveform.shape)
#torch.Size([2, 99368])
plt.plot(waveform.t().numpy());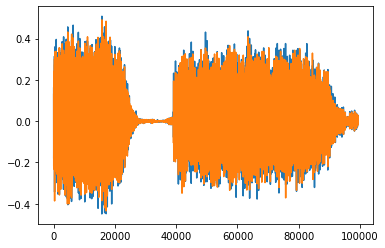
第三引数num_framesで、読み込む音源のサンプル数を指定できる。ここでは、サンプル数を10000に設定したため、読み込まれる音源の長さが10000になっていることが確認できる。
waveform, sample_rate = torchaudio.load(filepath=SAMPLE_WAV_PATH, num_frames=10000)
print(waveform.shape)
# torch.Size([2, 10000])
plt.plot(waveform.t().numpy());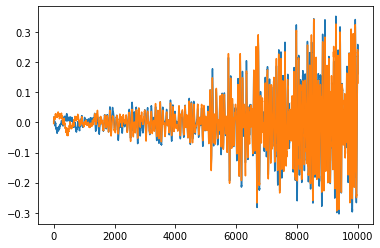
第二引数frame_offset、第三引数num_framesで、を設定することで、読み込みの開始サンプル点と読み込みサンプル数を設定でき、信号の任意の部分のみを読み込みできる。
waveform, sample_rate = torchaudio.load(filepath=SAMPLE_WAV_PATH, frame_offset=10000, num_frames=3000)
print(waveform.shape)
# torch.Size([2, 3000])
plt.plot(waveform.t().numpy());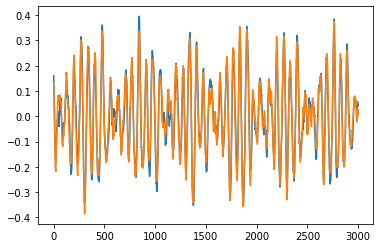
torchaudio.loadで読み込み可能なファイル形式
torchaudio.loadでは、以下ファイル形式を読み込むことができます。
- WAV, AMB
- 32-bit floating-point
- 32-bit signed integer
- 24-bit signed integer
- 16-bit signed integer
- 8-bit unsigned integer (WAV only)
- MP3
- FLAC
- OGG/VORBIS
- OPUS
- SPHERE
- AMR-NB
コメント