
音楽とオーディオ分析のPythonライブラリであるlibrosaで、音声/音楽データを読み込むにはlibrosa.loadを用いる。
今回用いるサンプル音源を、以下コードを実行して、_sample_dataフォルダにダウンロードする。
import os
import requests
_SAMPLE_DIR = "_sample_data"
SAMPLE_WAV_URL = "https://pytorch-tutorial-assets.s3.amazonaws.com/steam-train-whistle-daniel_simon.wav"
SAMPLE_WAV_PATH = os.path.join(_SAMPLE_DIR, "steam.wav")
os.makedirs(_SAMPLE_DIR, exist_ok=True)
with open(SAMPLE_WAV_PATH, 'wb') as f:
f.write(requests.get(SAMPLE_WAV_URL).content)librosa.loadの使い方
第一引数filepathに、音源のファイルパスを指定する。第二引数srに'None'、第三引数monoに'False'を指定することで、元のサンプリング周波数のまま、ステレオ音源がnumpy.ndarray型で[channel, time]で返ってくる。また、音源のサンプリング周波数も返ってくる。ステレオ(2ch)のため、表示すると青線と赤線が確認できる。
import librosa
import matplotlib.pyplot as plt
y, sr = librosa.load(SAMPLE_WAV_PATH, sr=None, mono=False)
print(y.shape)
# (2, 109368)
print(type(y))
# <class 'numpy.ndarray'>
print(sr)
# 44100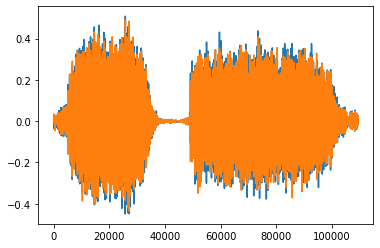
第二引数srのデフォルト値は22050、第三引数monoのデフォルト値は'True'に指定されており、そのまま読み込むと元の音源のまま読み込まれないので注意が必要である。デフォルト値のままだと、22050Hzでリサンプリングされ、ステレオ音源が足し合わされて読みこまれる。
y, sr = librosa.load(SAMPLE_WAV_PATH)
print(y.shape)
# (54684,)
print(type(y))
# <class 'numpy.ndarray'>
print(sr)
# 22050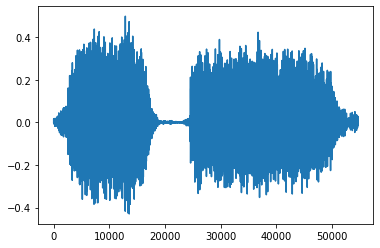
第二引数srで特定の周波数を指定すれば、その周波数にリサンプリングして音源を読み込んでくれるため、非常に便利である。
y, sr = librosa.load(SAMPLE_WAV_PATH, sr=None)
print(sr)
# 44100
y, sr = librosa.load(SAMPLE_WAV_PATH, sr=22050)
print(sr)
# 22050
y, sr = librosa.load(SAMPLE_WAV_PATH, sr=16000)
print(sr)
# 16000第四引数のoffsetで、音源の読み込み開始時間、第五引数のdurationで、音源の読み込む長さを指定することができる。offset=1、duration=1に指定した場合は、音源の1秒地点から1秒間(44100samples = sr*1)読み込まれる。
y, sr = librosa.load(SAMPLE_WAV_PATH, sr=None, mono=False, offset=1, duration=1)
print(y.shape)
# (2, 44100)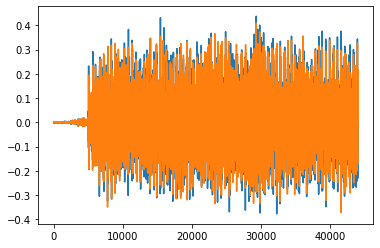
関連記事、関連資料
- 関連記事 – PyTorchで音声/音楽データを読み込むtorchaudio.load
- 関連記事 – SciPyで音声/音楽データを読み込むscipy.io.wavfile.read【Python】
- 関連記事 – PySoundFileで音声/音楽データを読み込むsoundfile.read【Python】
- GitHubコード

python-sampler/librosa-load.ipynb at main · take-tech-09/python-sampler
Contribute to take-tech-09/python-sampler development by creating an account on GitHub.
github.com
コメント