
音声強調、音声認識や音環境分類のような音データにおけるデータ拡張方法であるSpecAugmentをPyTrochで試す。PyTorchには、FrequencyMasking、TimeMaskingとTimeStretchの3つのクラスが用意されている。
データ拡張する対象の音源を、以下コードでダウンロードし、スペクトログラムに変換する。
import os
import requests
import librosa
import matplotlib.pyplot as plt
import torch
import torchaudio
import torchaudio.transforms as T
# 音声の保存
_SAMPLE_DIR = "_sample_data"
SAMPLE_WAV_URL = "<https://pytorch-tutorial-assets.s3.amazonaws.com/VOiCES_devkit/source-16k/train/sp0307/Lab41-SRI-VOiCES-src-sp0307-ch127535-sg0042.wav>"
SAMPLE_WAV_PATH = os.path.join(_SAMPLE_DIR, "speech.wav")
os.makedirs(_SAMPLE_DIR, exist_ok=True)
with open(SAMPLE_WAV_PATH, 'wb') as f:
f.write(requests.get(SAMPLE_WAV_URL).content)
# スペクトログラム表示用関数
def plot_spectrogram(spec, title=None, ylabel="freq_bin", aspect="auto", xmax=None):
fig, axs = plt.subplots(1, 1)
axs.set_title(title or "Spectrogram (db)")
axs.set_ylabel(ylabel)
axs.set_xlabel("frame")
im = axs.imshow(librosa.power_to_db(spec), origin="lower", aspect=aspect)
if xmax:
axs.set_xlim((0, xmax))
fig.colorbar(im, ax=axs)
plt.show(block=False)
# 音源の読み込み
waveform, sample_rate = torchaudio.load(filepath=SAMPLE_WAV_PATH)
n_fft = 1024
win_length = None
hop_length = 512
window_fn = torch.hann_window
# スペクトログラムに変換
spectrogram = T.Spectrogram(
n_fft=n_fft,
win_length=win_length,
hop_length=hop_length,
window_fn=window_fn,
power=2.0,
)
spec = spectrogram(waveform)
# 表示
plot_spectrogram(spec[0], title='torchaudio')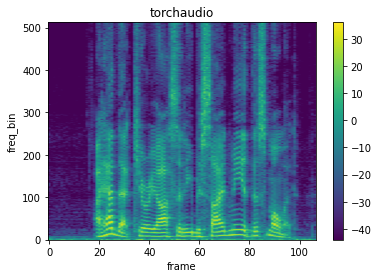
TimeMaskingの使い方
torchaudio.transforms.TimeMaskingの引数time_mask_paramに、マスクする最大のサンプルサイズを指定し、オブジェクトを生成します。生成したオブジェクトの入力にTensor配列(スペクトログラム)を指定するとマスクされたTensor配列(スペクトログラム)が出力されます。 スペクトログラムでマスクされる範囲は、[0, time_mask_param]からランダムに毎回選択されます。
import torchaudio.transforms as T
masking = T.TimeMasking(time_mask_param=50)
spec_masking = masking(spec)
# 元のスペクトログラム
plot_spectrogram(spec[0], title='Original')
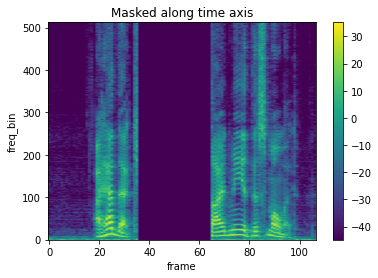
# TimeMasking処理後のスペクトログラム1
plot_spectrogram(spec_masking[0], title="Masked along time axis")
spec_masking2 = masking(spec)
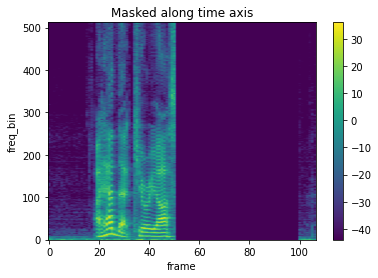
# TimeMasking処理後のスペクトログラム2
plot_spectrogram(spec_masking2[0], title="Masked along time axis")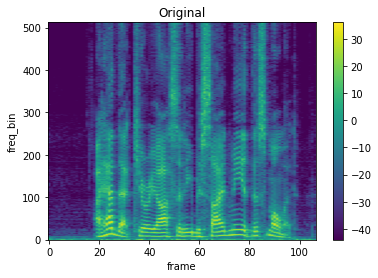
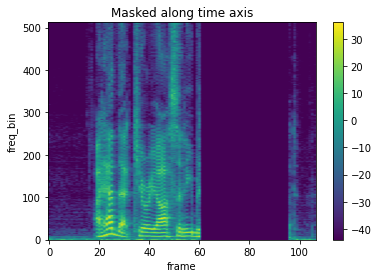
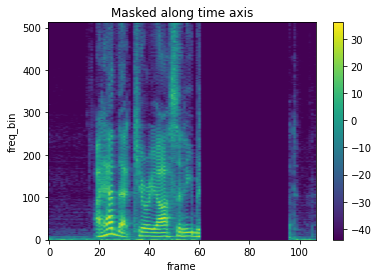
バッチ内で異なるマスクを使うには
引数iid_masksはデフォルトでFalseになっており、バッチ内で同じマスクが適用される。
- iid_masks=Falseの場合
# batchサイズ2のTensor行列を作成
spec_batch = torch.cat((spec, spec), dim=0).unsqueeze(dim=1)
print(spec_batch.shape)
# torch.Size([2, 1, 513, 107])
masking = T.TimeMasking(time_mask_param=50, iid_masks=False)
spec_masking = masking(spec_batch)
# sample1
plot_spectrogram(spec_masking[0,0,:,:], title="Masked along time axis")
# sample2
plot_spectrogram(spec_masking[1,0,:,:], title="Masked along time axis")
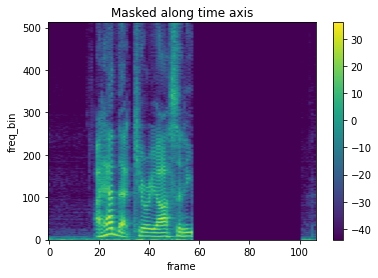
- iid_masks=Trueの場合
バッチ内でも異なるマスクが適用される。
masking = T.TimeMasking(time_mask_param=50, iid_masks=True)
spec_masking = masking(spec_batch)
# sample1
plot_spectrogram(spec_masking[0,0,:,:], title="Masked along time axis")
# sample2
plot_spectrogram(spec_masking[1,0,:,:], title="Masked along time axis")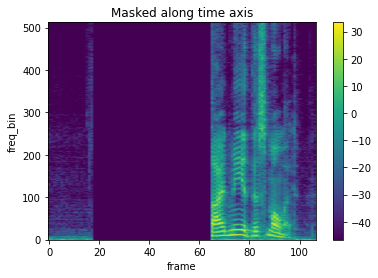
マスクを適用する確率の指定
引数pで、マスクを適用する確率を指定することができる。範囲は0.0~1.0で、デフォルト値は1.0である。
masking = T.TimeMasking(time_mask_param=50, iid_masks=True, p=0.5)FrequencyMaskingの使い方
torchaudio.transforms.FrequencyMaskingの引数freq_mask_paramに、マスクする最大のサンプルサイズを指定し、オブジェクトを生成します。生成したオブジェクトの入力にTensor配列(スペクトログラム)を指定するとマスクされたTensor配列(スペクトログラム)が出力されます。 スペクトログラムでマスクされる範囲は、[0, freq_mask_param]からランダムに毎回選択されます。
masking = T.FrequencyMasking(freq_mask_param=50)
spec_masking = masking(spec)
# FrequencyMasking処理後のスペクトログラム1
plot_spectrogram(spec_masking[0], title="Masked along frequency axis")
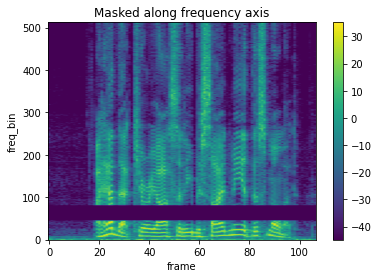
spec_masking2 = masking(spec)
# FrequencyMasking処理後のスペクトログラム2
plot_spectrogram(spec_masking2[0], title="Masked along frequency axis")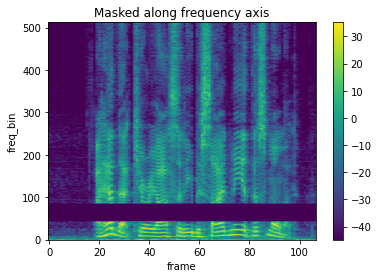
バッチ内で異なるマスクを使うには
TimeMaskingと同様に引数iid_masksは、デフォルトでFalseになっており、バッチ内で同じマスクが適用されるため、iid_masks=Trueにすることで、バッチ内で異なるマスクを適用できる。
spec_batch = torch.cat((spec, spec), dim=0).unsqueeze(dim=1)
print(spec_batch.shape)
# torch.Size([2, 1, 513, 107])
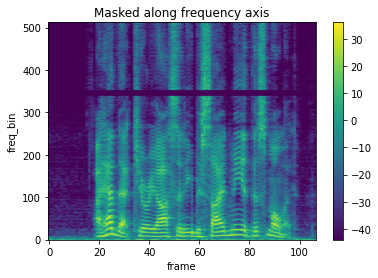
masking = T.FrequencyMasking(freq_mask_param=50, iid_masks=True)
spec_masking = masking(spec_batch)
# sample1
plot_spectrogram(spec_masking[0,0,:,:], title="Masked along frequency axis")
# sample2
plot_spectrogram(spec_masking[1,0,:,:], title="Masked along frequency axis")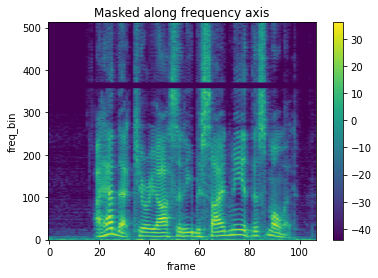
TimeStretchの使い方
torchaudio.transforms.TimeStretchの引数n_freqに周波数binの数を指定しオブジェクトを作成し、引数にスペクトログラム(Tensor配列)とストレッチするrateを指定する。
import torchaudio.transforms as T
stretch = T.TimeStretch(n_freq=spec.shape[1])
# 元のスペクトログラム
plot_spectrogram(spec[0], title='Original', xmax=107)
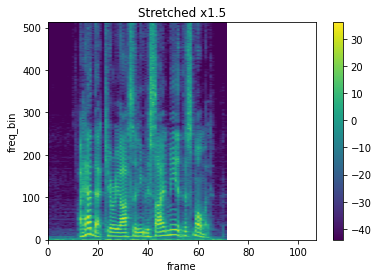
rate = 1.5
spec_stretch = stretch(spec, rate)
# sample1
plot_spectrogram(spec_stretch[0], title=f"Stretched x{rate}", xmax=107)
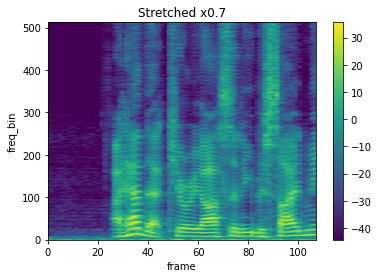
rate = 0.7
spec_stretch = stretch(spec, rate)
# sample2
plot_spectrogram(spec_stretch[0], title=f"Stretched x{rate}", xmax=107)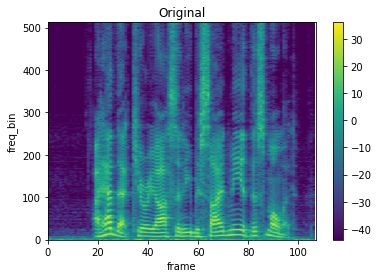
コメント