
「ゼロから作るDeep Learning ❷ ―自然言語処理編」の第6章前半を読んだので概要をメモ

ゼロから作るDeep Learning ❷ ―自然言語処理編
第6章ゲート付きRNN
「RNN」と言った時、それが指すレイヤは前章のRNNではなく、LSTMであることが多い。
第5章までに紹介した「RNN」は、「シンプルなRNN」、「エルマン」と呼ばれる。
「シンプルなRNN」は、あまり性能が良くなく、時系列データの長期依存関係を上手く学習できない。一方で、LSTMやGRUは「ゲート」と呼ばれる仕組みが加わっており、時系列データの長期的な依存関係を学習することができるようになっている。
RNNの問題点-勾配消失もしくは勾配爆発
「シンプルなRNN」が、時系列データの長期依存関係を上手く学習できない理由は、BPTT(Backpropagation Through Time)において、勾配消失もしくは勾配爆発が起こることに原因がある。
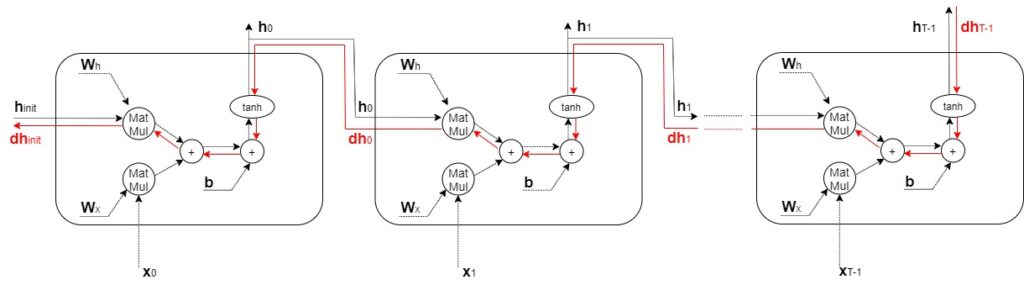
(図)RNNレイヤの時間方向の勾配の伝播の、時間方向の勾配に着目すると、「tanh」、「+」、「MatMul」の演算を行なうことが分かる。
+の逆伝播
勾配をそのまま流すだけのため、値は変わらない。
tanhの逆伝播
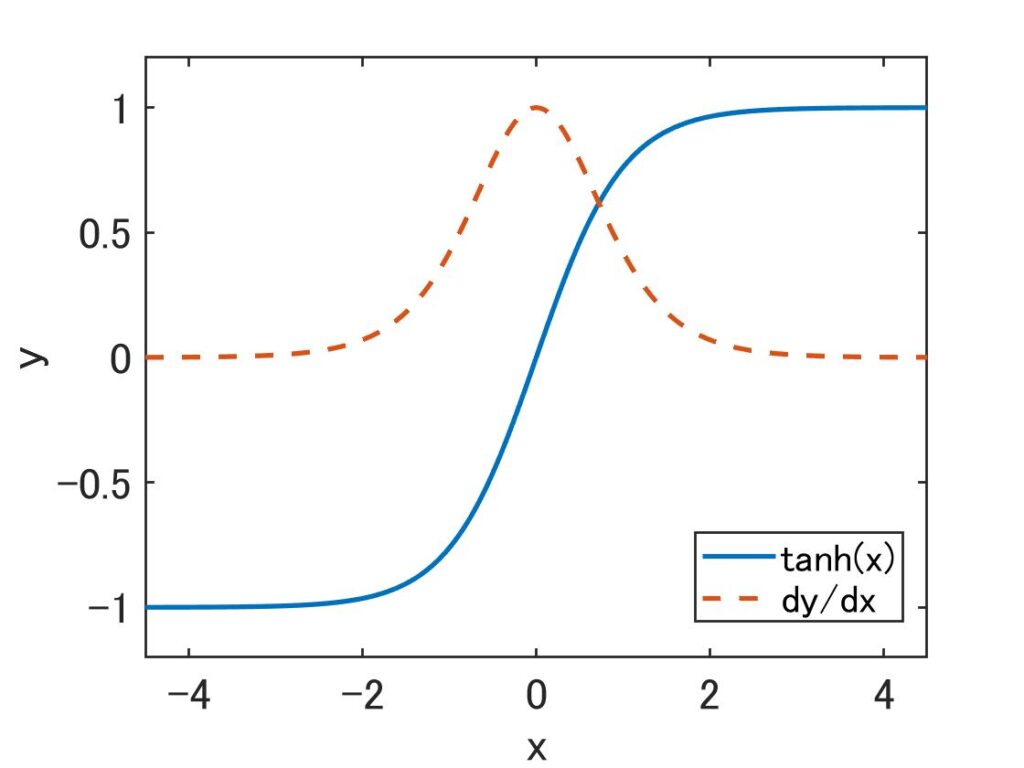
tanhの微分は1.0以下となるため、tanhを通るたびに、値がどんどん小さくなっていくため、勾配は弱められる。
※活性化関数にReLUに変えることで勾配消失を抑えることが期待できる
MatMul(行列の積)の逆伝播

単純化するために、tanhノードを無視したRNNレイヤの逆伝播の勾配は、図のように「MatMul」の演算によってのみ変化することがわかる。dhWhによる行列の積によって勾配が計算され、時系列データの時間サイズ分だけ繰り返される。
この行列の積には、毎回同じ重みであるWhが使われるため、勾配の大きさは繰り返すたびに、指数的に増加/減少する。
勾配爆発
勾配の大きさが発散し、最終的にオーバーフローを起こして、NaNのような値が発生する。
勾配消失
勾配の大きさが小さくなりすぎることで、重みパラメータが更新されずに、長期的な依存関係を学習できなくなる
※行列の「特異値」の最大値が1より大きい場合は、指数的に増加する可能性が高く。特異値が1より小さい場合は、指数的に減少する。
勾配クリッピング
勾配爆発対策の定番の手法で、非常に簡単な方法。
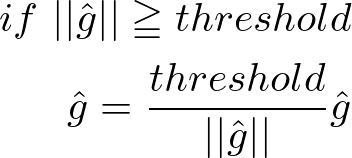
gは、ニューラルネットワークで使われるすべてのパラメータに対する勾配を一つにまとめたもの。勾配のL2ノルムがしきい値を超えた場合に、上記式のように勾配を修正する。
勾配消失とLSTM
「シンプルなRNN」では、勾配消失の対策が難しく、アーキテクチャを根本から変える必要がある。ここで登場するのがゲート付きRNNで、代表格にLSTMとGRUがある。
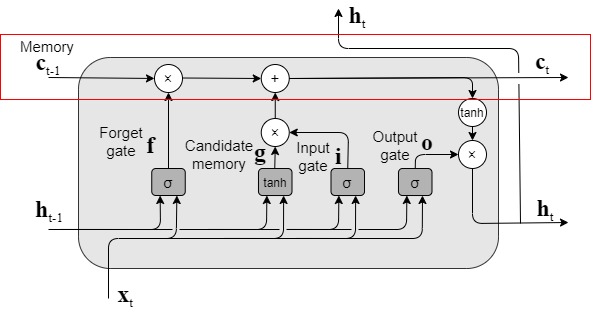
LSTM
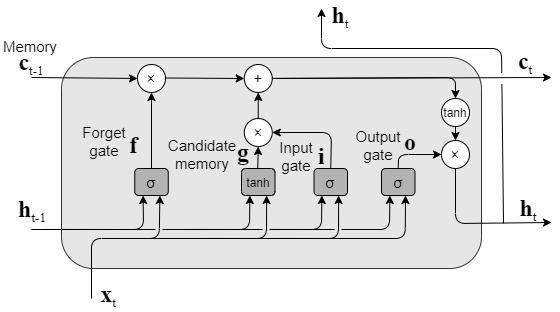
LSTMの全体構成は図のようになっており、「シンプルRNN」と比較すると、構造は複雑であるが、外部的にはcが追加されたのみであること分かる。このcは記憶セルと呼ばれ長期的な依存関係を学習するのに役立つ。
cは長期的な記憶、hは短期的な記憶を意味している。
LSTMのキーアイディアcとゲート
cは長期的な記憶を保存するセルで、乗算部で長期的な記憶をどの程度削除するか決め、加算部で長期的な記憶にどの程度新しい情報を追加するか決める。
ゲートは選択的に情報を通す仕組みで、シグモイドニューラルネットワーク層と一点の乗算により構成されている。
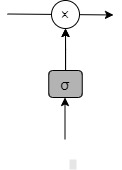
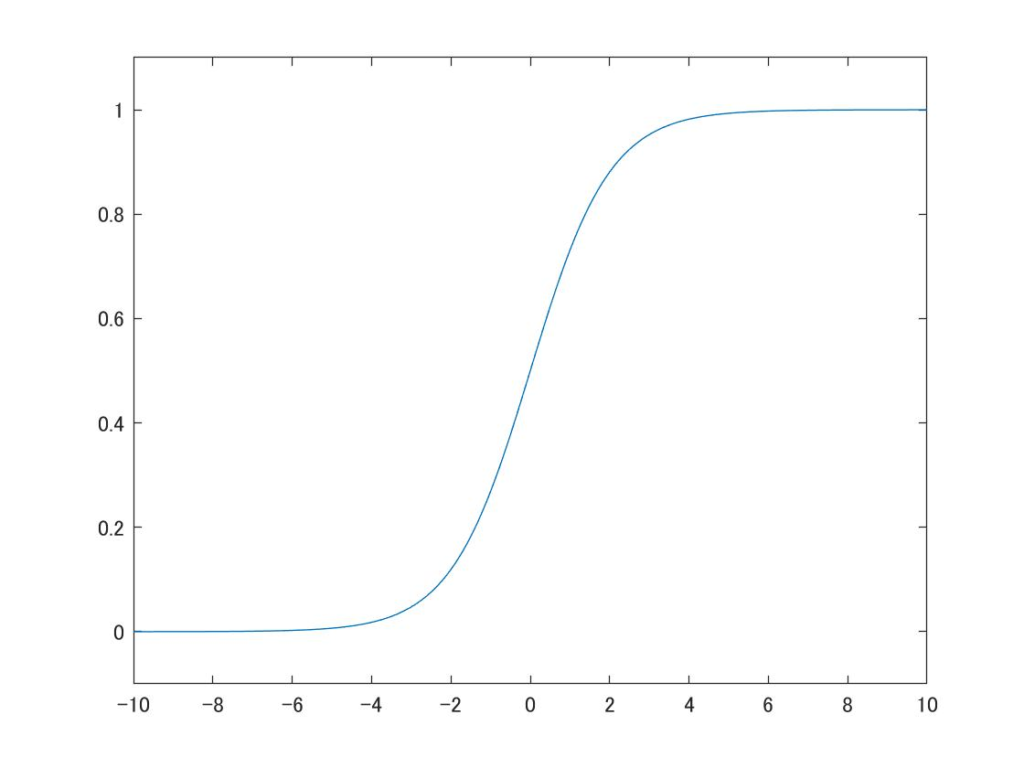
シグモイド関数は0~1までの数値を出力するので、0であれば情報を通さず、1であれば情報を通される。
%7D%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
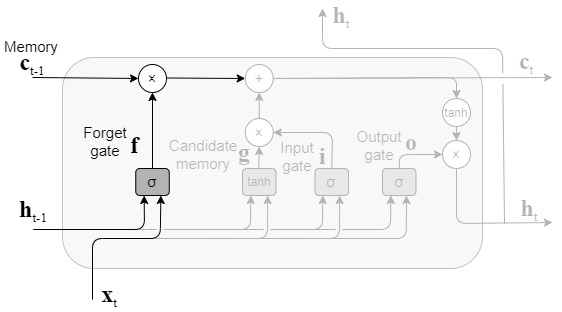
forgetゲート
forgetゲートでは、記憶セルから不要な記憶を忘れる働きをする。
%7D%2B%5Cmathbf%7Bh%7D%7Bt-1%7D%5Cmathbf%7BW%7D%7B%5Cmathbf%7Bh%7D%7D%5E%7B(f)%7D%2B%5Cmathbf%7Bb%7D%5E%7Bf%7D)%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
forgetゲートの出力fは上記式によって求められ、ct-1との要素の積によってctが求められる。
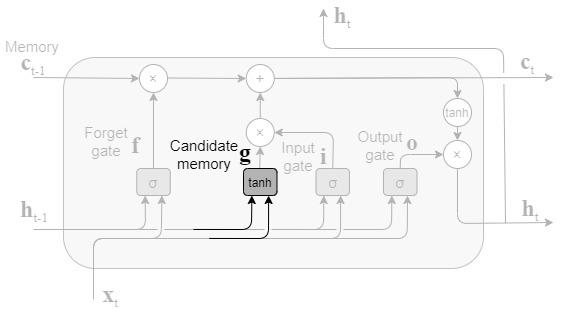
新しい記憶セルとinputゲート
forgetゲートによって、前時刻の記憶セルから忘れるべき情報が削除されたが、このままだと記憶セルは忘れることしかできない。このため、新しく覚えるべき情報を記憶セルに追加する。
%7D%2B%5Cmathbf%7Bh%7D%7Bt-1%7D%5Cmathbf%7BW%7D%7B%5Cmathbf%7Bh%7D%7D%5E%7B(g)%7D%2B%5Cmathbf%7Bb%7D%5E%7Bg%7D)%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
上記式より、新しく覚えるべき情報の候補gが算出される。ゲートではなく、新しい情報を生成するため、活性化関数はtanhが使われる。
ここで、gはそのまま記憶セルct-1に追加されず、inputゲートによって追加する情報の取捨選択が行われ、ct-1に追加される。
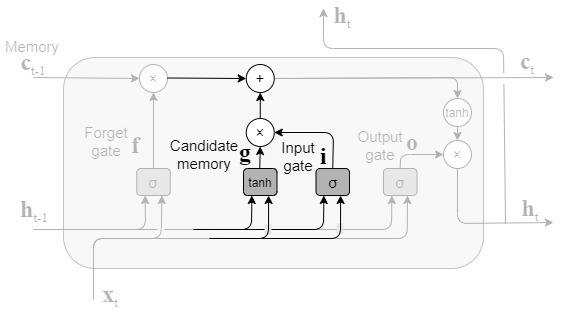
%7D%2B%5Cmathbf%7Bh%7D%7Bt-1%7D%5Cmathbf%7BW%7D%7B%5Cmathbf%7Bh%7D%7D%5E%7B(i)%7D%2B%5Cmathbf%7Bb%7D%5E%7Bi%7D)%5C%5C%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
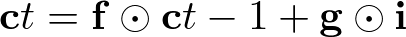
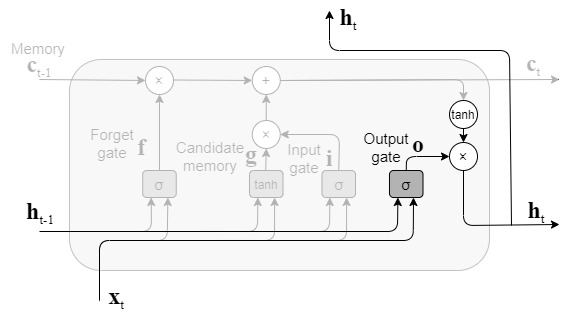
outputゲート
記憶セルctにtanh関数を適用することで隠れ状態htを出力するが、ここでもゲートを適用することで、tanh(ct)が次時刻の隠れ状態としてどれだけ重要か調整される。
%7D%2B%5Cmathbf%7Bh%7D%7Bt-1%7D%5Cmathbf%7BW%7D%7B%5Cmathbf%7Bh%7D%7D%5E%7B(o)%7D%2B%5Cmathbf%7Bb%7D%5E%7Bo%7D)%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
LSTMの勾配の流れ

記憶セルの逆伝播では、「+」と「×」ノードだけを通ることになる。「+」ノードは、勾配をそのまま流すだけなので、勾配の変化は起きない。「×」は、要素ごとの積で、毎時刻、異なるゲート値によって要素ごとの積の計算が行われるため、勾配消失を起こしにくい。
コメント