
「ゼロから作るDeep Learning ❷ ―自然言語処理編」の第4章を読んだので概要をメモ

ゼロから作るDeep Learning ❷ ―自然言語処理編
4章 word2vecの高速化
前章で実装したword2vec(CBOW)モデルの場合、コーパスで扱う語彙数が増えるに従って、計算量が増加し、実用レベルでは多くの時間がかかってしまう。そこで本章では、word2vecの高速化に主眼を置き、改善に取り組む。
4.1 word2vecの改良①
100万語彙数など巨大コーパスを扱う場合、前章実装のCBOWでは計算量が問題
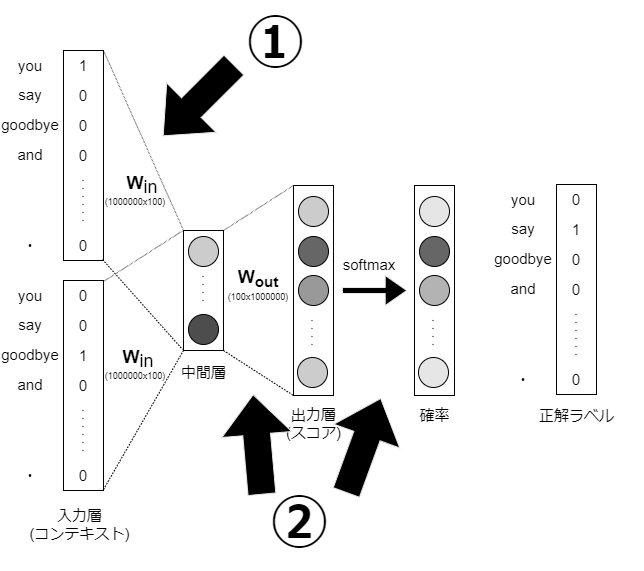
①入力層のone-hot表現と重み行列Win積による計算
→4.1節で Embeddingレイヤーを導入することで解決
②中間層と重み行列Woutの積およびsoftmaxレイヤの計算
→4.2節で Negative Samplingという損失関数を導入することで解決
Embeddingレイヤ
コンテキスト(one-hot)とWinの積の計算は、Winの行ベクトル抜き出し同じ
これより、積の計算するレイヤ(MatMulレイヤ)から、行を抽出するレイヤ(Embeddingレイヤ)に置き換えることで計算量を削減。
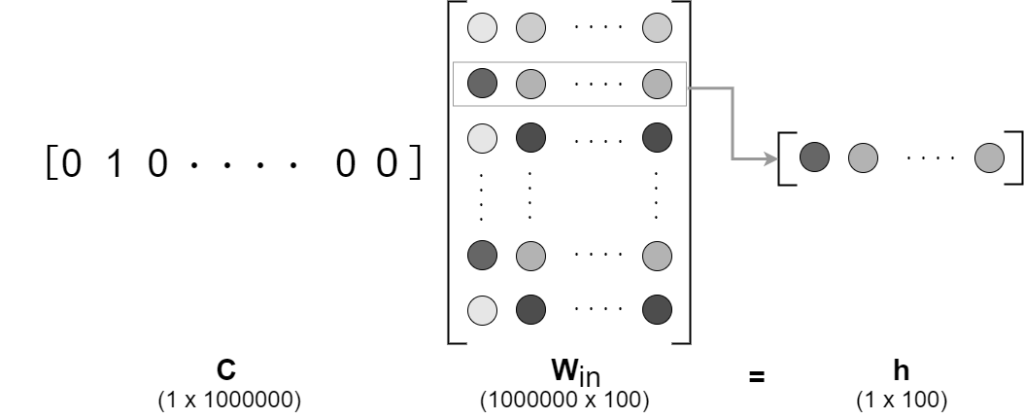
※Embeddingとは、単語の埋め込みという用語に由来。このレイヤに単語の分散表現が格納される。
Embeddingレイヤの実装
順伝播では、行をそのまま抜き出す
逆伝播では、前層から伝わる勾配を、重みの勾配 $\bf{dW}$の特定の行に設定する
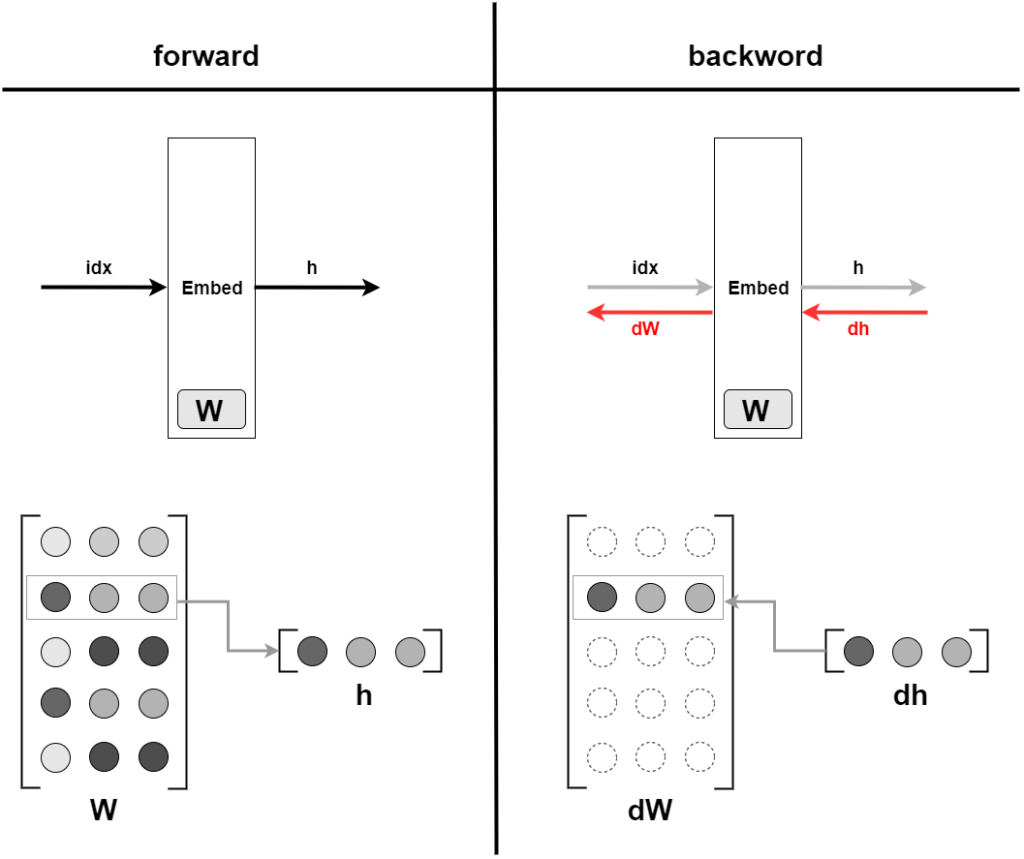
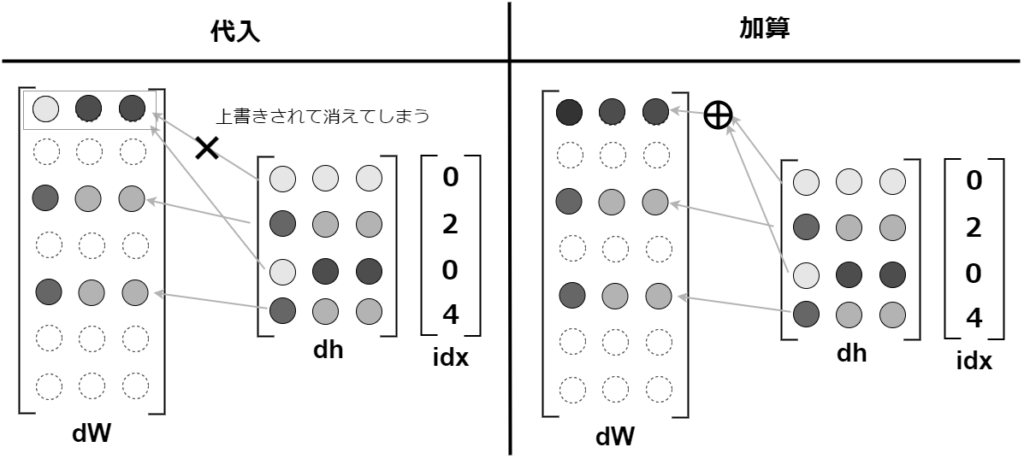
逆伝播のidxが重複する可能性があり、重みの勾配 dWが上書きされてしまう問題が発生
この重複問題に対応するために、「代入」ではなく「加算」を行なう
4.2 word2vecの改良②
この章では、中間層と重み行列Woutの積およびsoftmaxレイヤの計算削減に取り組む
中間層と重み行列の積で計算量が多くなるのは、前章と同様である。softmaxレイヤでも語彙数が増えるに従い、計算量が増加する。softmaxの式を見てみる。
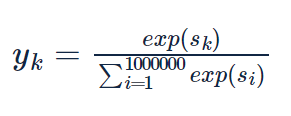
語彙数に応じて、expの計算をする必要があることがわかる。このため、Softmaxに代わる軽い計算が求められる。
多値分類から二値分類へ
Negative Samplingのキーとなるアイディアは「二値分類」による「多値分類」の近似
これまで扱ってきた問題を、コンテキストが「you」、「goodbye」の時、ターゲットとなる単語は「say」ですか?という質問にすれば「二値分類」として答えることができる。
これにより、「二値分類」に対応するニューラルネットワークすることができ、出力層にはニューロンを一つだけ用意するだけで事足りる。
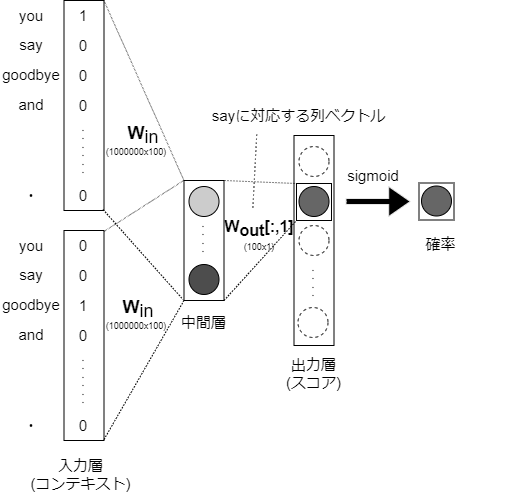
出力層のニューロンが一つのため、中間層と出力層の重み行列の積は、「say」に対応する列だけ抽出し、その抽出したベクトルと中間層のニューロンの内積を計算すれば良い
シグモイド関数と交差エントロピー誤差
スコアの算出にシグモイド関数を適用し、確率を得る。
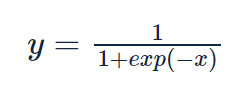
損失関数として、「交差エントロピー誤差」を使用する。yはシグモイド関数の出力、tは正解ラベルで、tは0か1のどちらかの値を取る。
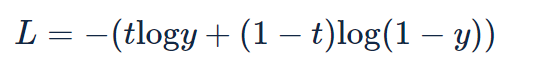
Negative Sampling
ここまで、正例(正しい答えに)の学習について考えて来たが、この場合だと負例の学習が無く良いモデルにすることができない。しかし、すべての負例を対象にして、二値分類の学習を行なうと、語彙数が増えるに従って計算量が手に負えなくなってしまう。
そこで、近似解として、負例をいくつか(5,10個とか)ピックアップして用いる。これを「Ngative Sampling」という
Ngative Sampling
正例をターゲットとした場合の損失+負例をいくつかサンプリングした損失 を最終的な損失とする
Negative Samplingのサンプリング手法
コーパス中の各単語の確率分布から、単語をサンプリングする。コーパス中で多く登場した単語は抽出されやすくなり、レアな単語は抽出されにくくなる。
※Negative Samplingでは元の確率分布に対して0.75を累乗することが提案されている。出現確率の低い単語を見捨てないようにするため
4.3 改良版word2vecの学習
実装なので省略。
4.4 word2vecに関する残りのテーマ
word2vecを使ったアプリケーションの例
- 単語の分散表現の利点
- 様々なタスクへの適用
- テキスト分類や文書クラスタリング、品詞タグ付け、感情分析など
- 機械学習の手法の適用が可能
- 固定長のベクトルとすることで、機械学習の入力にできる
- 単語の分散表現は、通常は学習済みのものを個別のタスクで利用
- WikipediaやGoogle Newsのテキストデータなどで学習を行い、学習済みの分散表現を利用
- メールの自動分類システムの例
単語ベクトルの評価方法
- アプリケーション(感情分析システムやテキスト分類)とは切り離して評価
- アプリケーションと、単語の分散表現のシステムは別のため学習や評価に多大な時間がかかってしまう
- 一般的によく使われる評価指標は「類似性」や「類推問題」による評価
- 単語の類似性の評価では、人間が作成した単語類似度の評価セットを使って評価
- 人が出したスコアとword2vecによるコサイン類似度のスコアを比較し相関性を見る
- 類推問題による評価は「king:queen = man: ?」のような問題を出題しその正解率をもって評価
コメント