
前回、GymnasiumでAtari Breakout(ブロック崩し)をランダムに動かすことができたので、ここではPyTorchによる強化学習(DQN)によってゲームを攻略していきます。最終的に、全ブロックを崩すことに成功しました。
PyTorch公式のDQNチュートリアルをベースに、Atari Breakoutで上手く動作していくように改良したメモです。ざっとしたメモなのでわからない箇所も多いと思います。なにかあれば気軽にコメントしてください。
学習
ライブラリのインストールとインポート
必要なライブラリのインストールとインポートをします。
pip install gymnasium[atari]
pip install gym[accept-rom-license]==0.21.0
pip install opencv-pythonimport random
import math
import gymnasium as gym
from collections import namedtuple, deque
from itertools import count
import cv2
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
%matplotlib inline
from IPython import display
from tqdm.notebook import tqdm
from ipywidgets import Output
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")Experience Replay Memory
DQNの学習では、Experience Replay Memoryが用いられます。大規模なFIFOに収集したデータを保存していき、学習時にはそこからランダムに取り出してモデルを更新します。これにより、サンプル間の相関を下げることができ、学習が大幅に安定することが知られています。
Experience Replay Memoryを実装するため、2つのクラスを作成します。
Transition:状態、アクション、次の状態、報酬のタプル
ReplayMemory:capacityでFIFOのメモリサイズを指定します。push()はデータを新しく保存することができ、sample()でbatch_size分、保存されているデータからランダムにデータを抽出します。
例えば、capacity=100に指定した場合、push()でデータを保存していくと100個までは保存されますが、101個目を保存する場合は、一番古いデータが破棄されます。ここでは、capacityを100000に指定しますが、Google Colabなどで動作させる場合は適宜メモリサイズを小さくしてください。1/10程度にすれば動作すると思います。
Transition = namedtuple('Transition',
('state', 'action', 'next_state', 'reward'))
class ReplayMemory(object):
def __init__(self, capacity): # capacityサイズのFIFOを生成
self.memory = deque([], maxlen=capacity)
def push(self, *args): # メモリにデータを入れる
self.memory.append(Transition(*args))
def sample(self, batch_size): # batch_size分ランダムにメモリから抽出
return random.sample(self.memory, batch_size)
def __len__(self):
return len(self.memory)
size_replay_memory = 100000 #メモリのサイズ ※Google ColabなどRAMサイズが小さい場合は10000程度にする
memory = ReplayMemory(capacity=size_replay_memory)モデル:Dueling Network
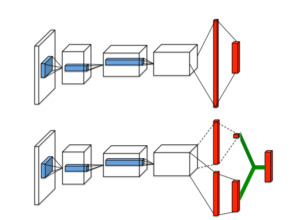
モデルはDQNを改良したDueling Networkを用いる。DQN(図上)に対して、Dueling Network(図下)は出力側を2つに分離することで、Q関数に対して状態とaction(Advantage)に分けて学習することができます。
class Dueling_Network(nn.Module):
def __init__(self, n_frame, n_actions):
super(Dueling_Network, self).__init__()
self.relu = nn.ReLU()
self.conv1 = nn.Conv2d(n_frame,32,8,4)
self.conv2 = nn.Conv2d(32,64,4,2)
self.conv3 = nn.Conv2d(64,64,3,1)
self.act_fc = nn.Linear(3136 , 512)
self.act_fc2 = nn.Linear(512, n_actions)
self.value_fc = nn.Linear(3136 , 512)
self.value_fc2 = nn.Linear(512, 1)
torch.nn.init.kaiming_normal_(self.conv1.weight)
torch.nn.init.kaiming_normal_(self.conv2.weight)
torch.nn.init.kaiming_normal_(self.conv3.weight)
torch.nn.init.kaiming_normal_(self.act_fc.weight)
torch.nn.init.kaiming_normal_(self.act_fc2.weight)
torch.nn.init.kaiming_normal_(self.value_fc.weight)
torch.nn.init.kaiming_normal_(self.value_fc2.weight)
self.flatten = nn.Flatten()
def forward(self, x):
x = self.relu(self.conv1(x))
x = self.relu(self.conv2(x))
x = self.relu(self.conv3(x))
x = self.flatten(x)
x_act = self.relu(self.act_fc(x))
x_act = self.act_fc2(x_act)
x_val = self.relu(self.value_fc(x))
x_val = self.value_fc2(x_val)
x_act_ave = torch.mean(x_act, dim=1, keepdim=True)
q = x_val + x_act - x_act_ave
return qε-greedy方策
ε-Greedy法を採用することで、ランダムな行動をさせ探索させます。学習初期は、eps_threshold が高くランダムな行動をしますが、学習が進むに連れてeps_thresholdが小さくなり、モデルによるアクションを出力します。
def e_greedy_select_action(state):
global steps_done
global fire_ball
eps_threshold = EPS_END + (EPS_START - EPS_END) * math.exp(-1. * steps_done / EPS_DECAY) # ランダムアクション選択の閾値を更新
steps_done += 1
if fire_ball: # ボールが落ちた場合は、強制的にボールを出す
fire_ball = False
return torch.tensor([[1]]), eps_threshold
elif random.random() > eps_threshold: # モデルによるアクション
with torch.no_grad():
return policy_net(state.to(device)).argmax().view(1, 1).cpu(), eps_threshold
else: # ランダムアクション
return torch.tensor([[env.action_space.sample()]]), eps_threshold
グレースケール化、リサイズとRandomErasing
使用メモリの削減のために、画像をグレースケール化しリサイズします。また、ブロックの状態に依存しすぎないように、ブロックがあるエリアのみRandomErasingを実施します。
def to_resize_gray(image, resize):
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)[32:,8:152] # プレイに関係ある部分のみ切り出し
image = cv2.resize(src=image, dsize=(resize, resize))/255. # 画像のリサイズと値の変換0~1
for _ in range(10): # ブロックのあるエリアをランダムに削除
if random.random() > 0.9:
x_p = random.randint(10, 25)
y_p = random.randint(0, 70)
image[x_p:x_p+4, y_p:y_p+10] = 0.0
image = torch.tensor(image, dtype=torch.float32).unsqueeze(0).unsqueeze(0)
return image
resize_image = 84
env = gym.make('ALE/Breakout-v5', render_mode="rgb_array")
state, info = env.reset(seed=random.randint(0, 2**24))
# オリジナルの画像の表示
plt.imshow(state)
plt.show()
# グレースケール、リサイズ、ランダム削除の画像表示
state = to_resize_gray(state, resize_image)
plt.imshow(state[0,0], cmap = "gray")
plt.show()
モデルの学習
PyTorchのチュートリアルコードをほとんどそのまま使えます。Replay Memoryに保存していたデータをランダムに取り出して学習させます。
def optimize_model():
if len(memory) < BATCH_SIZE:
return
transitions = memory.sample(BATCH_SIZE)
batch = Transition(*zip(*transitions))
non_final_mask = torch.tensor(tuple(map(lambda s: s is not None,
batch.next_state)), device=device, dtype=torch.bool)
non_final_next_states = torch.cat([s for s in batch.next_state
if s is not None])
state_batch = torch.cat(batch.state).to(device)
action_batch = torch.cat(batch.action).to(device)
reward_batch = torch.cat(batch.reward).to(device)
state_action_values = policy_net(state_batch).gather(1, action_batch)
next_state_values = torch.zeros(BATCH_SIZE, device=device)
with torch.no_grad():
next_state_values[non_final_mask] = target_net(non_final_next_states.to(device)).max(1)[0]
expected_state_action_values = (next_state_values * GAMMA) + reward_batch
criterion = nn.SmoothL1Loss()
loss = criterion(state_action_values, expected_state_action_values.unsqueeze(1))
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_value_(policy_net.parameters(), 1000)
optimizer.step()
以下のコードで学習を始めます。工夫した箇所は下記の点になります。
- 過去フレームの活用
1frameの画像だけの場合、その次ボールがどこに動くか分からないため、過去数フレームを利用する。今回は6フレームを利用しました。 - 報酬のクリッピング
- 未来の報酬の追加とライフ消失時のマイナス報酬
未来の報酬をより強く利用することで、現在のアクションがより正しいか判断させやすくした。ライフ消失時にマイナスの報酬を与えることで、ボールを打ち返しやすくしました。
num_episodes = 5000000 # 学習させるエピソード数
n_frame = 6 # 過去フレームの利用数
resize_image = 84 # リサイズ後のピクセル数
reward_clipping = True # 報酬のクリッピング
BATCH_SIZE = 256 # バッチサイズ
# ε-greedy方策パラメータ
GAMMA = 0.99
EPS_START = 1.0
EPS_END = 0.01
EPS_DECAY = 25000000
# モデル更新パラメータ
TAU = 0.005
LR = 1e-4
num_episode_plot = 2500 # 何エピソードで学習の進捗を確認するか
num_episode_save = 25000 # 何エピソードでモデルを保存するか
# モデルの初期化
env = gym.make('ALE/Breakout-v5', render_mode="rgb_array")
n_actions = env.action_space.n
policy_net = Dueling_Network(n_frame, n_actions).to(device)
target_net = Dueling_Network(n_frame, n_actions).to(device)
target_net.load_state_dict(policy_net.state_dict())
optimizer = optim.AdamW(policy_net.parameters(), lr=LR, amsgrad=True)terminated = True
frame1 = True
total_steps = 0
count_update = 0
steps_done = 0
reward_all = -num_episode_plot*0.75+1
reward_durations = []
out = Output()
display.display(out)
for i_episode in tqdm(range(num_episodes)):
fire_ball = True # エピソードの初めは必ずボールを出すアクションにする
reward_frame = torch.tensor([0], dtype=torch.float32)
if terminated == True:
state_frame = torch.zeros((1, n_frame, resize_image, resize_image), dtype=torch.float32)
next_state_frame = torch.zeros((1, n_frame, resize_image, resize_image), dtype=torch.float32)
state, info = env.reset(seed=random.randint(0, 2**24))
state = to_resize_gray(state, resize_image)
state_frame[:,0,:,:] = state
next_state_frame[:,0,:,:] = state
old_life = info['lives']
for t in count():
total_steps +=1
action, eps_threshold = e_greedy_select_action(state_frame)
observation, reward, terminated, truncated, info = env.step(action.item())
if old_life > info['lives']: # ライフが減った場合にtruncatedをTrueにして次エピソードにする
old_life = info['lives']
truncated = True
done = terminated or truncated
if done: # ライフが減った場合にマイナスの報酬を与える
reward = -1
reward = torch.tensor([reward])
reward_all += reward
if reward_clipping: # 報酬のクリッピング
reward = torch.clamp(input=reward, min=-1, max=1)
next_state = to_resize_gray(observation, resize_image)
# rollして一番古いフレームを新しいフレームで上書きする
next_state_frame = torch.roll(input=next_state_frame, shifts=1, dims=1)
next_state_frame[:,0,:,:] = next_state
if frame1 == True:
state_frame1 = state_frame
action_frame1 = action
next_state_frame1 = next_state_frame
if done:
next_state_frame1 = None
frame1 = False
reward_frame += reward
if (total_steps % n_frame == 0) or done:
memory.push(state_frame1, action_frame1, next_state_frame1, reward_frame)
frame1 = True
reward_frame = torch.tensor([0], dtype=torch.float32)
count_update += 1
if count_update % 4 == 0:
if count_update > size_replay_memory:
optimize_model()
if count_update % 400 == 0:
target_net_state_dict = target_net.state_dict()
policy_net_state_dict = policy_net.state_dict()
for key in policy_net_state_dict:
target_net_state_dict[key] = policy_net_state_dict[key]*TAU + target_net_state_dict[key]*(1-TAU)
target_net.load_state_dict(target_net_state_dict)
state_frame = next_state_frame
if done:
break
if (i_episode % num_episode_plot == 0):
reward_durations.append(reward_all/num_episode_plot)
with out:
plt.figure(1)
plt.clf()
plt.xlabel('Episode')
plt.ylabel('Reward')
plt.plot(np.arange(0, (i_episode/num_episode_plot+1)*num_episode_plot, num_episode_plot), torch.tensor(reward_durations, dtype=torch.float).numpy())
display.display(plt.gcf())
display.clear_output(wait=True)
if (i_episode % num_episode_save) == 0:
torch.save(target_net.state_dict(), str(i_episode)+'.pth')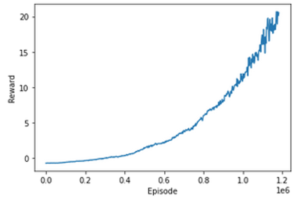
学習モデルでのプレイ
学習させたモデルにゲームをプレイさせます。
import gymnasium as gym
import cv2
import matplotlib
import matplotlib.pyplot as plt
%matplotlib inline
from IPython import display
import torch
import torch.nn as nn
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
env = gym.make('ALE/Breakout-v5', render_mode="rgb_array")
resize = 84
n_frame = 6
n_actions = env.action_space.n
state, info = env.reset()
old_life = info['lives']
n_observations = len(state.flatten())
target_net = Dueling_Network(n_frame, n_actions).to(device)
target_net.load_state_dict(torch.load('600000.pth'))
target_net.eval()
state_frames = torch.zeros((1, n_frame, resize, resize), dtype=torch.float32, device=device)
observation, reward, terminated, truncated, info = env.step(1)
observation_frame = cv2.cvtColor(observation, cv2.COLOR_BGR2GRAY)/255.
observation_frame = cv2.resize(src=observation_frame[32:,8:152], dsize=(resize, resize))
state_frames[:,0,:,:] = torch.tensor(observation_frame, dtype=torch.float32, device=device).unsqueeze(0)
while True:
action = target_net(state_frames).argmax().view(1, 1)
if old_life > info['lives']:
old_life = info['lives']
action = 1
observation, reward, terminated, truncated, info = env.step(action)
plt.imshow(observation)
display.display(plt.gcf())
display.clear_output(wait=True)
observation_frame = cv2.cvtColor(observation, cv2.COLOR_BGR2GRAY)/255.
observation_frame = cv2.resize(src=observation_frame[32:,8:152], dsize=(resize, resize))
observation_frame = torch.tensor(observation_frame, dtype=torch.float32, device=device).unsqueeze(0)
state_frames = torch.roll(input=state_frames, shifts=1, dims=1)
state_frames[:,0,:,:] = observation_frame
if terminated or truncated:
break0エピソード学習
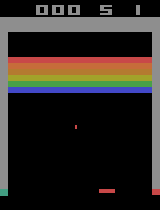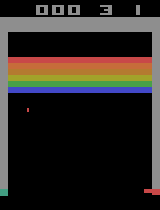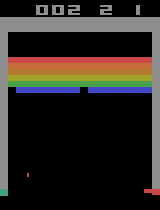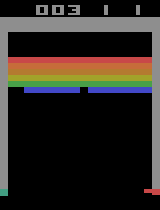
600000エピソード学習
12000000エピソード学習
全ブロックを崩すことができました!

コメント
このPytorchのプログラムの実行時間はどれくらいかかったのですか?また、実行は継続して行っていたのですか?もし途中中断をして再開するという工程を経て、結果クリアとなったのであればそのやり方を教えていたただきたいです。(Google Colabで実行しているので、制限時間があるため、、)
RTX3090を用いて、5~7日間くらい継続して学習させました。途中中断して実行したことはないのですが、中断時にmodelとReplayMemoryを保存して、中断後にそれぞれ読み出せば上手くいくと思います。
返信ありがとうございます。中断後に保存するファイルは.pth ファイルというのはわかるのですが、ReplayMemoryが保存されているかがわからないのと、中断後に読み出すやり方がわからないです。教えていただいけたらありがたいです。
ReplayMemoryは、修正しないといけないので、とりあえずモデルのみで動作をみるのが良いと思います。
モデルの読み込み
こちらを参考に、以下箇所でモデルを読み込めば良いと思います。
policy_net = Dueling_Network(n_frame, n_actions).to(device)target_net = Dueling_Network(n_frame, n_actions).to(device)
ありがとうございます。試してみます!